Cuestiones sobre ASP.NET
21 marzo, 2006
Fuente: Revista dotNetManía
Este mes responderemos algunas preguntas relacionadas con el desarrollo Web y ASP.NET en particular. Las cuestiones abordan temas que van desde la importación de datos desde fuentes externas y sitios Web, hasta tareas asíncronas y la representación de imágenes almacenadas en bases de datos
Algunos de los sitios Web que visito regularmente muestran información actualizable desde otros sitios: por ejemplo noticias deportivas. No creo que ninguno de mis clientes realmente quisiera tal tipo de servicio pero sí que pienso que la importación de datos externos desde otros sitios Web sería una poderosa característica a considerar.
Hasta donde yo sé, hay dos formas típicas de implementar algo similar. Una consiste en utilizar un servicio Web para obtener cualquier información contractual expuesta por el sitio. Esto significa, sobre todo, algún tipo de acuerdo entre las dos partes. Cuanta más información valiosa, más tendrás que pagar por ella, probablemente. Desde un punto de vista tecnológico, simplemente se accede a la información de entrada (normalmente, cadenas), y la muestras en la forma adecuada. El segundo enfoque, supone suscribirse a algún origen de datos RSS. Es un sitio que expone información publicable y la hace disponible, virtualmente a cualquier cliente, gratis. En este caso, abres un “socket” hacia el destino RSS, obtienes la información (una cadena XML) y la incorporas en tus páginas.
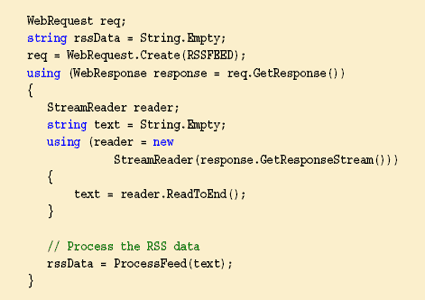
Para leer orígenes RSS, se utilizan típicamente herramientas como RssBandit o SharpReader. ¿Cómo podrías leer uno de estos orígenes en una página ASP.NET? Lo que muchos sitios Web hacen es utilizar un control de usuario compuesto.
En ambos casos, un acuerdo implícito o explícito existe entre tu sitio y el del origen de la información. Pero, para decirlo todo, existe un tercer enfoque: el clásico “screen scrapping”. Aunque nacida históricamente en “mainframes” hace 25 años, la técnica recobró actualidad con el advenimiento de las páginas Web. Consiste en la posibilidad de descargar una página completa y analizarla para extraer la información válida. Por ejemplo, se puede descargar una página de cotizaciones de bolsa, y mostrar solo aquellas en las que estas interesado. Se analizan los contenidos eliminando todo menos los 3 ó 4 valores a buscar.
Si el sitio Web de origen no tiene una oferta RSS, ésta sería mi opción predilecta. “Screen-scrapping” debería considerarse únicamente como último recurso. Para leer orígenes RSS, se utilizan típicamente herramientas como RssBandit o SharpReader.
¿Cómo podrías leer uno de estos orígenes en una página ASP.NET?
Lo que muchos sitios Web hacen (incluyendo las páginas MSDN) es utilizar un control de usuario compuesto. La clave de este control, contendría un código similar al siguiente:
Cualquier operación puede ser fácilmente catalogada en dos formas: vinculada a la CPU o a un proceso de entrada/salida.
La variable text contiene la salida del origen en formato XML. El contenedor ProcessFeed recorre los elementos XML y construye un texto imprimible en HTML. Si seleccionamos una aproximación más elegante, podríamos devolver un array de objetos personalizados a partir de ProcessFeed que solamente almacenaran líneas individuales para ser transformadas en lenguaje de marcas posteriormente. El código siguiente muestra cómo construir una lista de enlaces a los últimos “posts”:

Este código puede ser fácilmente incorporado en un control de usuario compuesto hecho a partir de una tabla o rejilla.
He construido varias soluciones utilizando tareas asíncronas, pero reconozco que no he prestado demasiada atención el término I/O bound. ¿Significa esto que cualquier operación asíncrona no estrictamente relacionada con entrada/salida es perniciosa?
Cualquier operación puede ser fácilmente catalogada en dos formas: vinculada a la CPU o a un proceso de entrada/salida. En el primer caso, el tiempo de compleción está determinado por las características de la propia CPU y la memoria disponible. En el otro, la situación es radicalmente distinta, y la CPU espera (la mayor parte del tiempo) a que los dispositivos de entrada/salida terminen su trabajo.
Ahora bien, ¿Cuál es el objetivo último de un proceso asíncrono? Un empleo típico es cuando necesitamos que nuestra interfaz de usuario no se “congele” mientras termina algún proceso en “background”, de larga duración potencial. En este sentido, no hay ninguna diferencia importante entre los dos tipos de operaciones. Esto es correcto en tanto que estemos considerando escenarios de “clientes ricos”, como aplicaciones Windows Forms. Para aplicaciones ASP.NET las cosas son algo distintas. Si has escrito ese código para aplicaciones Windows no debe de haber problema.
La necesidad del proceso asíncrono deriva de un tiempo excesivo en el tráfico de la información de entrada/salida, respecto del tiempo de proceso.
¿Qué operaciones son buenos candidatos a implementarse como páginas Web asíncronas? Para decirlo en otra forma, ¿que operaciones requieren, o al menos, sugieren claramente la adopción de páginas asíncronas en una aplicación ASP.NET?
Intentemos formalizar brevemente el concepto de proceso asíncrono dentro del contexto de ASP.NET.
La necesidad del proceso asíncrono deriva de un tiempo excesivo en el tráfico de la información de entrada/salida, respecto del tiempo de proceso. En tales situaciones, la CPU está en estado de espera o es infrautilizada la mayor parte del tiempo, esperando que algo suceda. Y en particular, en las operaciones de entrada/salida en el contexto de ASP.NET, por que los subprocesos en servicio están bloqueados también y el ?pool? de servicio de subprocesos es un recurso finito y crítico.
Se obtienen mejoras en el rendimiento si se utilizan modelos asíncronos en operaciones de entrada/salida. En la implementación de .NET Framework, cuando se hace una llamada asíncrona no existen subprocesos bloqueados mientras la operación está pendiente.
Ejemplos típicos de operaciones de entrada/salida son todas las operaciones que requieren acceso a algún tipo de recurso remoto o que interaccionan con dispositivos hardware externos. Las operaciones sobre bases de datos o servicios Web no locales, son las más comunes para considerar la creación de páginas asíncronas.
En ASP.NET, las operaciones de larga duración de CPU (por ejemplo, algún algoritmo que requiera actuar sobre datos en memoria) son también buenas candidatas a una implementación asíncrona para mantener en número de subprocesos administrados en un nivel suficientemente alto. En este caso, sin embargo, todavía está recargada con algo de trabajo, y la ganancia de rendimiento es menor que en las operaciones de entrada/salida.
En suma, cualquier tarea de larga duración debería de ser llamada de forma asíncrona, tanto en Windows como en ASP.NET. En este último caso, sin embargo, es particularmente importante en los procesos de entrada/salida. Si uno de estos procesos (por ejemplo, la llamada a un servicio Web), es implementado de forma asíncrona, la CPU del servidor no se ve afectada, y puede procesar con prontitud otras peticiones. Para operaciones vinculadas a la CPU, también las llamadas asíncronas pueden ofrecer algo de mejora en Windows, al ejecutarse en un subproceso diferente. Para aplicaciones ASP.NET, sin embargo, no debieran esperarse grandes mejoras. Siempre es mejor la llamada asíncrona pero las páginas se mostrarán lentamente, ya que la CPU tiene que realizar un gran trabajo para generarlas. Una aproximación más eficaz sería separar las operaciones de larga duración a un servidor remoto y transformar la tarea tipo CPU en una del tipo entrada/salida.
En los primeros días de ASP.NET 2.0 (trabajo con ella desde las primeras versiones alpha, en verano de 2003) podía referenciar fácilmente imágenes almacenadas en una base de datos SQL Server usando el control <asp_DynamicImage> Este control, fue eliminado en posteriores “releases” y en la versión final. Sin embargo, el problema que me condujo a esa situación al principio no desaparece. ¿Cómo puedo construir mi propio control de imagen dinámico en ASP.NET 2.0?
Cualquiera que sea el origen de la imagen a mostrar, sólo puede incluirse en una página a través del elemento y, por consiguiente, vía URL
En ASP.NET, dispones de dos controles de servidor para mostrar imágenes: image y HtmlImage. Ambos controles suministran un ligero nivel de abstracción sobre algunas de las propiedades del elemento de HTML. Ambos controles, en definitiva, sólo permiten referenciar imágenes vía URL, y establecer algunos atributos de presentación.
Como sugieres, en el mundo real, los gráficos pueden venir de una gran variedad de orígenes. Por ejemplo, pueden provenir de un fichero, se pueden leer a partir de un campo de una base de datos, o se pueden generar dinámicamente en memoria utilizando una API gráfica. Sólo en el primer caso (el del fichero en disco) podemos aplicar adecuadamente el elemento y el API de ASP.NET. En todos los otros casos, los programadores deben escribir su propio código para conseguirlo. Veamos cómo.
El hecho es que, cualquiera que sea el origen de la imagen a mostrar, sólo puede incluirse en una página a través del elemento y, por consiguiente, vía URL. Toda la lógica empleada para obtener la imagen, debe de ser embebida en código accesible a través de una URL. En ASP.NET, la URL puede apuntar a un manejador HTTP personalizado. El control DynamicImage, de hecho, se apoya en el manejador cacheimageservice.axd, un manejador incrustado que ha sido liberado de la plataforma en alguna manera.
En ASP.NET 2.0, comienzas por crear un manejador análogo HTTP y diseñarle para aceptar en la cadena de consulta cualquier información que pueda ser útil para identificar la imagen y su origen. El viejo control DynamicImage encapsulaba mucha de esta información (cadenas de conexión, consultas, ID) en sus propios parámetros, aislando, por tanto, el manejador HTTP subyacente del desarrollador. Este manejador ejecutará cualquier código necesario para obtener los bytes de la imagen, establecer el tipo MIME apropiado y devolver los bytes. Para evitar consultas repetitivas y algunos ciclos de CPU, el manejador HTTP puede almacenar imágenes en el Cache y acceder a ellas la próxima vez que se necesiten.
Dino Esposito para dotNetManía